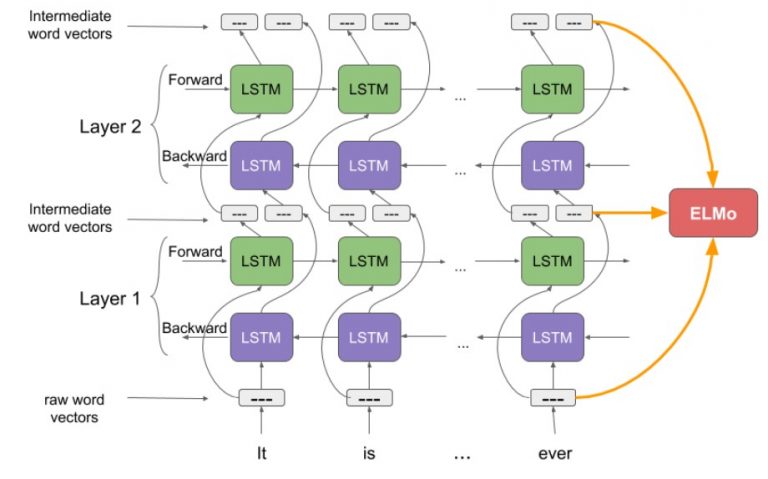
Gambar 1. Ilustrasi arsitektur yang menghasilkan ELMo (https://www.analyticsvidhya.com/blog/2019/03/learn-to-use-elmo-to-extract-features-from-text/)
Ada yang tau tentang Elmo? mungkin hampir semua sudah mengetahui salah satu karakter dari Sesame Street yang berwarna merah ini. Tapi dalam artikel ini, kita tidak akan membahas Elmo yang lucu itu, tetapi ELMo yang merupakan salah satu contextual embedding. Menurut paper yang mempropose tentang ELMo yaitu Deep Contextualized Word Representation (https://aclanthology.org/N18-1202/), ELMo mempunyai 2 kelebihan yaitu: (1) ELMo mampu memodelkan complex characteristic dari penggunaan sebuah kata (misal syntactic atau semantic) dan yang ke (2) ELMo mampu memodelkan variasi penggunaan karateristik pada poin 1 (misal polisemi). Lalu bagaimana sebetulnya ELMo dihasilkan? Gambar 1 memperlihatkan ilustrasi dari arsitektur yang menghasilkan ELMo
- Arsitektur ELMo menggunakan character-level CNN untuk merepresentasikan tiap kata pada input ke dalam raw word vector. Vector ini berfungsi sebagai input untuk layer pertama pada Bidirectional LSTM
- Forward pass pada BiLSTM mengandung informasi sebuah kata dan kata sebelumnya . Sebaliknya, Backward pass mengandung informasi sebuah kata dan kata setelahnya.
- Kedua informasi ini akan membentuk intermediate word vectors yang menjadi input untuk layer BiLSTM berikutnya.
- ELMo kemudian dibentuk dari weighted sum dari raw word vector dan 2 intermediate word vector





{kind=link}
{kind=link}